티스토리 뷰
카프카 탄생 배경

- 어플리케이션 아키텍쳐가 거대해지고, 소스 애플리케이션과 타깃 애플리케이션의 개수가 점점 많아지면서 문제가 생김
- LinkedIn 데이터 팀에서 내부 데이터 흐름을 개선하기 위해서 한곳에 데이터를 모아서 처리할 수 있도록 중앙집중화 구조를 가진 카프카를 고안함
카프카 내부 구조

- 카프카의 파티션 내부구조는 메시지 큐와 동일한 FIFO 구조
- 토픽 : 데이터의 구분에 따라 생성. 테이블과 같은 개념, 한개 이상의 파티션을 가짐
- 프로듀셔 : 큐에 데이터를 보내는 것 → 특정 데이터 (메시지) 가 내부 로직에 따라 여러 파티션 중 하나에 적재됨
- 컨슈머 : 데이터를 가져감
- 파티션 : 큐 구조 → 컨슈머가 데이터를 가져가더라도 큐에서 데이터가 삭제되지 않음.
카프카가 데이터 파이프라인으로 적합한 이유
- 높은 처리량
- 카프카는 프로듀서가 브로커로 데이터를 보낼 때 컨슈머가 브로커로부터 데이터를 받을 때 모두 묶어서 전송
- 데이터 량이 많을 때 카프카에서 배치로 데이터를 묶어서 보낼 수 있는 옵션이 있음
- 파티션 단위를 통해 동일 목적의 데이터를 여러 파티션에 분배하고 데이터를 병렬처리 할 수 있음
- 확장성
- 카프카는 가변적인 환경에서 안정적으로 확장 가능하도록 설계되어있음
- 데이터에 따라 브로커 개수를 자연스럽게 늘려 스케일 아웃, 스케일인 할 수 있음
- 무중단 운영을 지원 265일 24시간 데이터를 처리해야하는 커머스, 은행 비지니스 모델에서 안정적 운영 가능
- 영속성
- 영속성 : 데이터를 생성한 프로그램이 종료되더라도 사라지지 않은 데이터의 특성
- 데이터를 메모리에 저장하지 않고 파일 시스템에 저장 → 운영체제 레벨에서 파일시스템을 활용하는 방법을 적용해 느리지 않으며, 장애 발생으로 급작스럽게 종료되더라도 안전하게 데이터 처리 가능
- 운영체제에서 파일 I/O 성능 향상을 위해 페이지 캐시 영역을 메모리에 따로 생성하여 사용하며, 카프카에서는 페이지 캐시 메모리 영역을 사용하여 한번 읽은 파일을 메모리에 저장하여 사용하기에 처리량이 높음
- 고가용성
- 카프카 클러스터는 3개이상의 서버들로 운영하기에 무중단으로 안전하고 지속적으로 데이터 처리 가능
- 클러스터로 이뤄져있기때문에 카프카는 데이터의 복제(replication)를 통해 고가용성의 특징이 있음
- 프로듀서로 전송받은 데이터를 여러 브로커 중 한1대의 브로커에만 저장하는 것이 아닌, 여러 브로커에 저장
빅데이터 아키텍쳐의 종류와 카프카의 미래
- 초기 빅데이터 플랫폼은 엔드 투 엔드로 각 서비스 애플리케이션으로부터 데이터 배치를 모음 → 유연X, 실시간 X, 히스토리 파악 X, 데이터 거버넌스 X
람다 아키텍쳐

- 배치레이어 : 특정 시간 타이밍마다 데이터를 일괄 처리
- 스피드레이어 : 서비스에서 생성되는 원천 데이터를 실시간으로 분석하는 용도로 사용 ( 카프카가 스피드레이어에 위치)
- 서빙 레이어: 가공된 데이터를 서비스 애플리케이션이 사용할 수 있도록 데이터 저장된 공간
- 람다 아키텍쳐의 한계
- 배치레이어와 스피드레이어가 나뉘어져 있어서 동일한 데이터를 처리할때 로직을 따로 짜야하는 이슈가 있음
카파 아키텍쳐
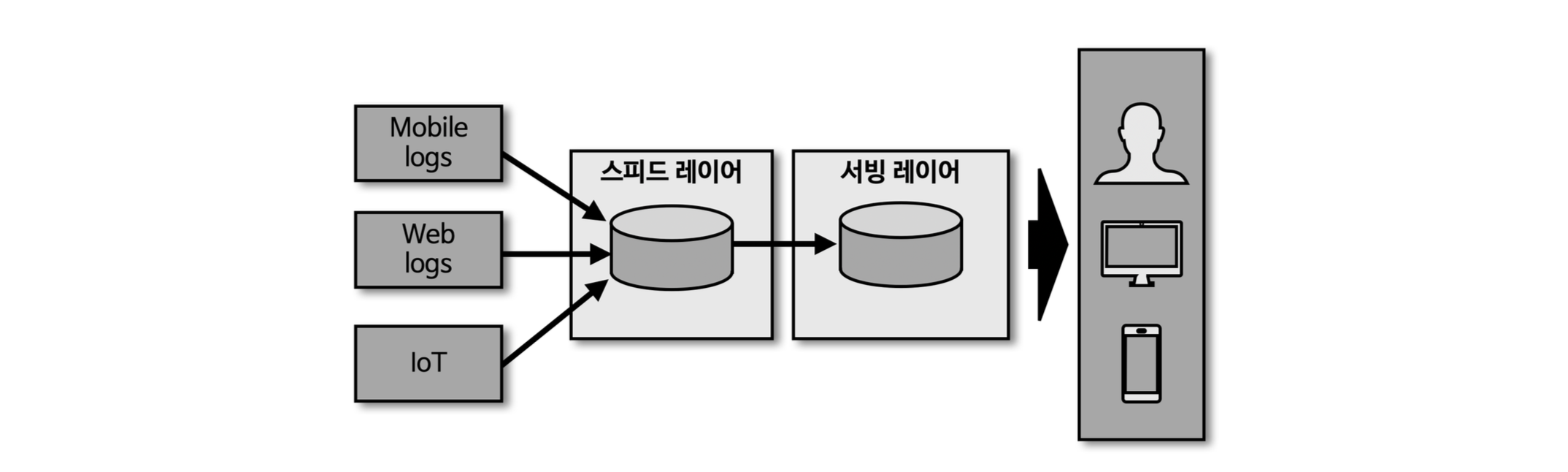
- 로직의 파편화, 디버깅, 배포, 운영 분리에 대한 이슈를 제거하기 위해 배치 레이어를 제기하여 스피드레이어(kafka) 에서 데이터를 모두 처리
- 스피드레이어에서 처리 방법
- 배치레이어를 제거 → 스트림 데이터를 배치 데이터로 활용
- 로그(타임스템프 필요)는 배치 데이터를 스트림으로 표현하기에 적합
- 배치 데이터를 스탭샷하고 변환 기록 로그를 통해 배치 데이터를 대신함
- ex. 2021년 신입생 목록 → 스트림 데이터로 적재된 1월 1일부터 12월 31일 까지 데이터를 구체화된 뷰로 가져와 배치로 처리
스트리밍 데이터 레이크 (제안 정도, 아직 실현 X)

- 카파 아키텍쳐에서 서빙 레이어를 제거한 아키텍쳐
- 서빙 레이어에서 가공하는 대용량 데이터까지 스피드레이어에서 오랜기간 저장하고 사용될 수 있다면 서빙 레이어는 필요 없다!
- 스트리밍 데이터 레이크를 사용하기 위해 몇가지 개선할 점이 필요함
- 자주 접근하지 않는 데이터를 굳이 비싼 자원(브로커의 메모리, 디스크)에 유지할 필요가 없음
- 자주사용하지 않는 데이터와 자주사용하는 데이터를 구분하여 분리하는 작업이 필요함.
- (참고) 배치 데이터 vs 스트림 데이터
- 배치데이터 :
- 한정된 데이터처리
- 대규모 배치 데이터를 위한 분산 처리 수행
- 분, 시간, 일 단위 처리를 위한 지연 발생
- 복잡한 키 조인 수행
- 스트림 데이터
- 무한으로 데이터 처리
- 지속적 데이터 분산처리 수행
- 분단위 이하 지연
- 단순한 키 조인 수행
« 2025/05 »
| 일 |
월 |
화 |
수 |
목 |
금 |
토 |
| |
|
|
|
1 |
2 |
3 |
| 4 |
5 |
6 |
7 |
8 |
9 |
10 |
| 11 |
12 |
13 |
14 |
15 |
16 |
17 |
| 18 |
19 |
20 |
21 |
22 |
23 |
24 |
| 25 |
26 |
27 |
28 |
29 |
30 |
31 |
